To give a slightly more concrete example, let’s imagine we wrote some integration routines and want the argument to these routines to be the user function. How should the call signature look? Should it be an std::function? A function pointer? Something else entirely? Does it even matter?
Unfortunately it does. For my many-body simulation I was facing this exact situation when looking for a way to implement user defined force calculations. The user should be able to pass a function that takes in two bodies and returns the pairwise interaction force between them, e.g. due to gravity or electromagnetic repulsion.
Roughly speaking, a naive many-body code has this structure:
for(int i=0; i<particles.size(); i++){
float acceleration = 0.0;
for(int j=0; j<particles.size(); j++){
acceleration += pairwise_force(particles[i], particles[j]);
}
}
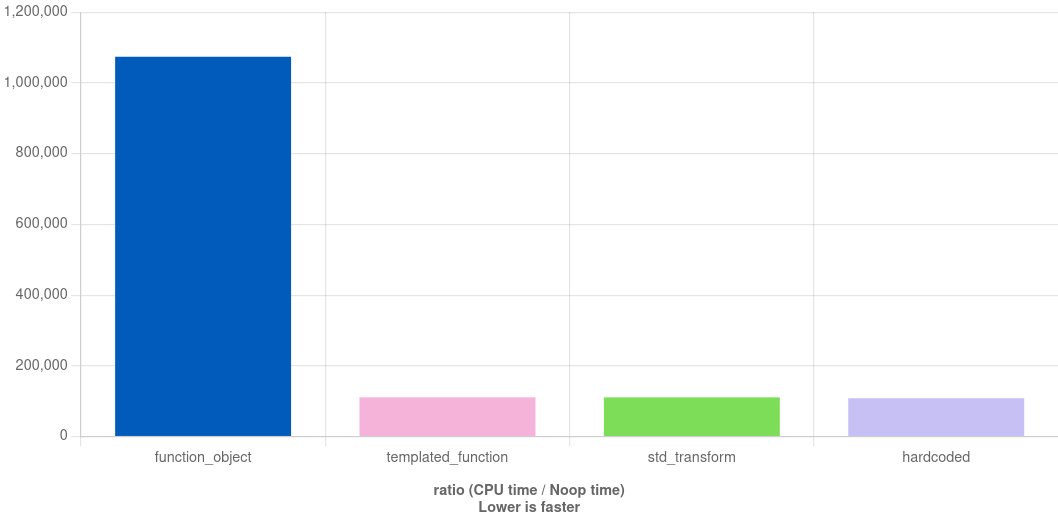
When refactoring from a hard coded force calculation to pairwise_force using a std::function<double(Particle, Particle)>, I immediately noticed a slowdown of 8-16x. Suspicious - that’s right around the vector length using AVX2 and single precision (256bit / 32bit = 8). Turns out, both Intel and GCC keep this as an entirely scalar loop, even if the same code was vectorizing perfectly fine before.
This is the case, even when both definitions are in the same translation unit. Passing a function pointer causes the same problem.
The solution is surprisingly simple! By making the argument pairwise_force of a template type instead of std::function<double(Particle, Particle)>, we force the compiler to inline the function. The result is a more readable, flexible implementation, where the user can pass their own force implementation (e.g. as a lambda function), without compromising runtime performance.
Compiler Explorer
Looking at the compiled assembly in Compiler Explorer reveals that the fast implementations were all successfully vectorized and use the YMM registers
.L21:
vmulpd ymm0, ymm1, YMMWORD PTR [rbx+rax]
vmovupd YMMWORD PTR [rdx+rax], ymm0
https://godbolt.org/z/zexbh1vTs
while the std::function implementation is stuck with XMM registers, that only hold one QWORD (64bit double)
std::_Function_handler<double (double, double), main::{lambda(double, double)#1}>::_M_invoke(std::_Any_data const&, double&&, double&&):
vmovsd xmm0, QWORD PTR [rsi]
vmulsd xmm0, xmm0, QWORD PTR [rdx]
https://godbolt.org/z/afGo1o1f1
References
- During my investigation I came across this great benchmark comparing different ways of passing function, that is applied to a vector of elements.
- Thanks for the helpful input by Fabio Gratl, developer of the amazing AutoPas library.